Hi all,
when trying to set up a grouped grid view on a table I faced a problem that looks like a more general one: using different values for the number of records to show gives different results ending up with some records showing up twice while others aren’t shown at all. As this happens even in the SQL Builder, I guess that something is wrong with the handling of partial SQL results.
A short example of what I’m talking about:
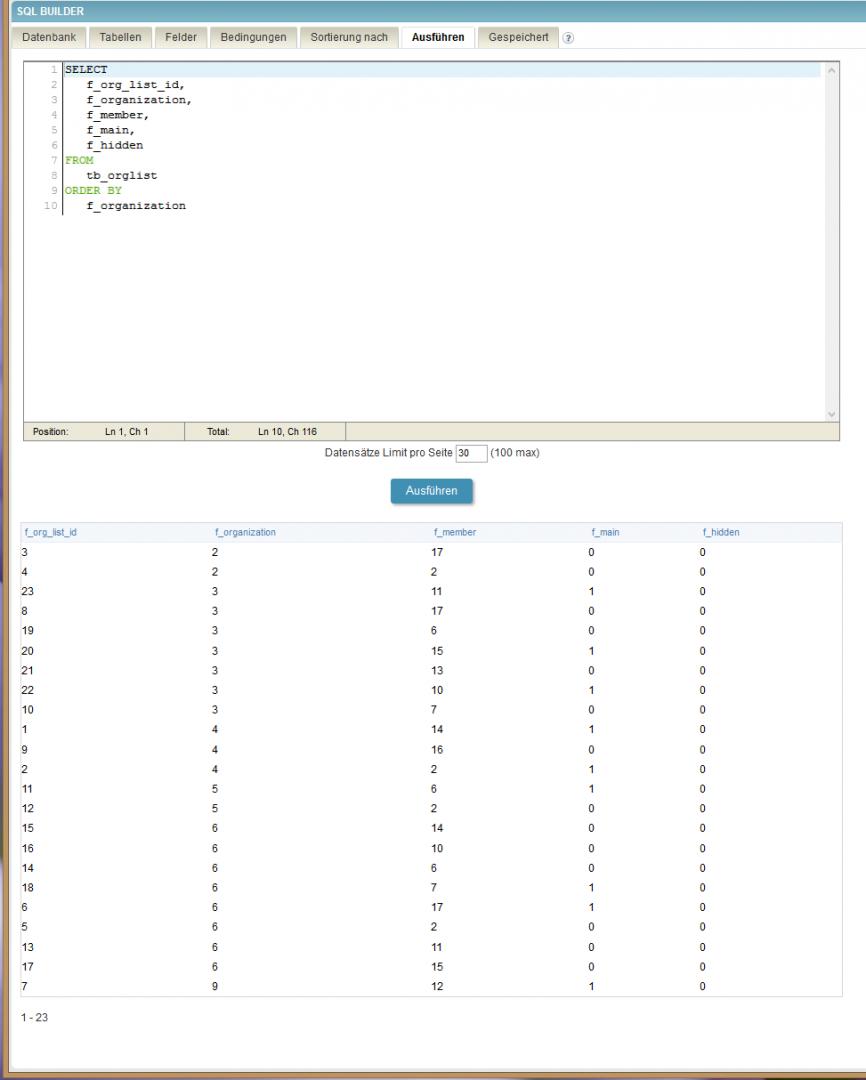
I have a table with 23 records. While stepping through them without grouping (just a standard SELECT - FROM SQL statement) showing 10 records a time everything is fine and works as expected. Now if I add a simple ORDER BY statement, things start to get confused. I would expect to see the same results, no matter the value I choose for the number of record sets to show at a time, but that’s not the case:
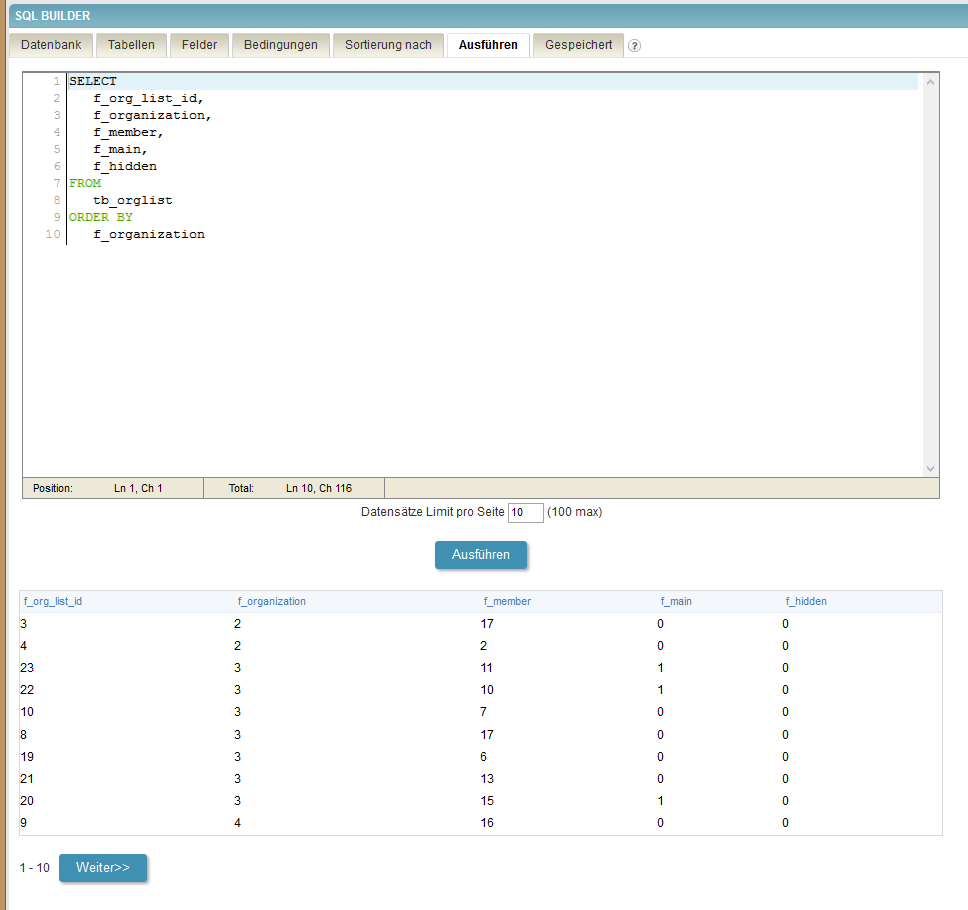
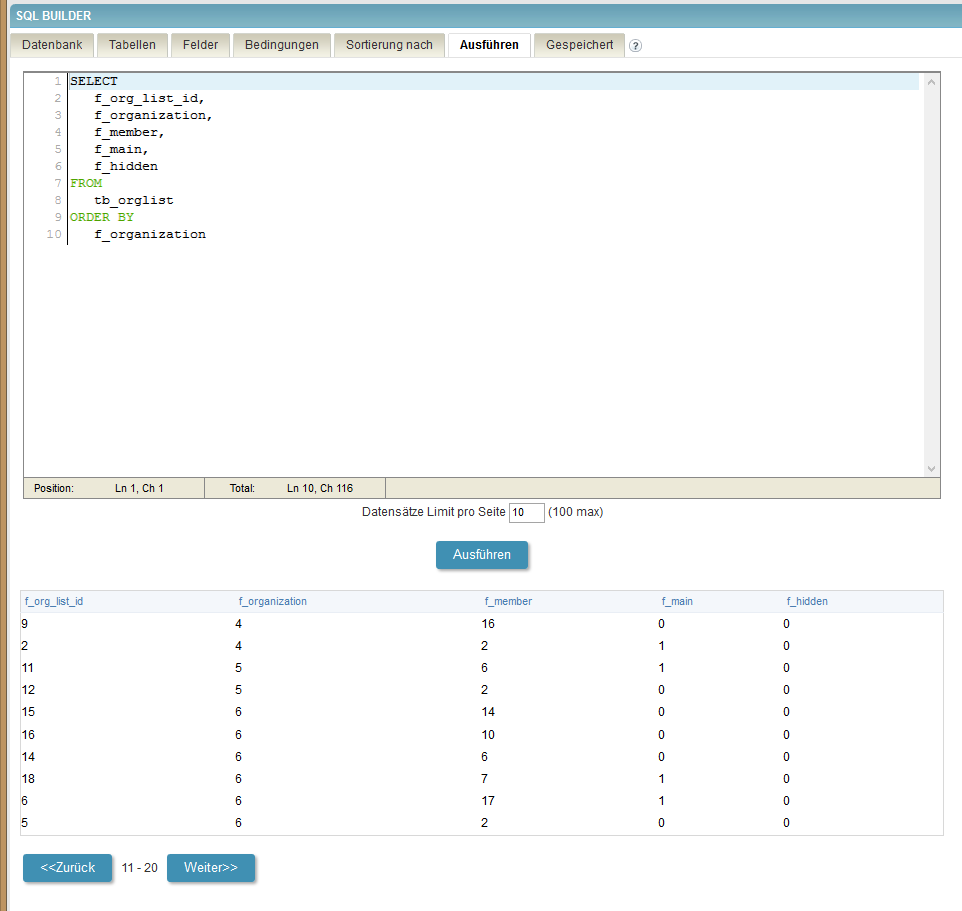
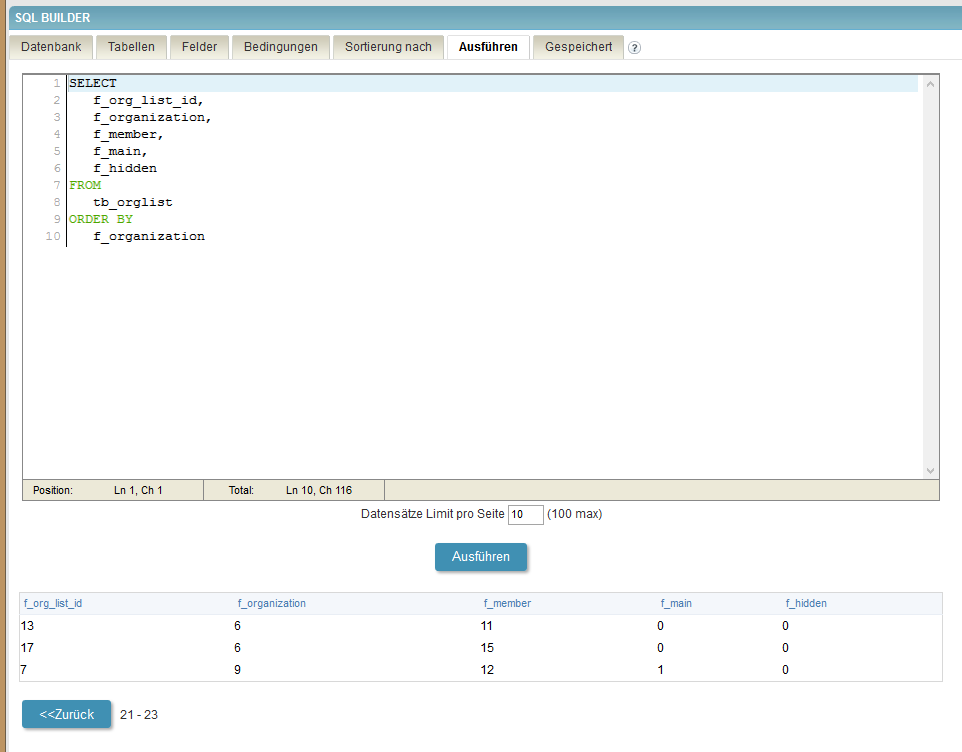
In the first picture you can see the expected result when showing all records at once. In the next pictures you can see the result if I limit the number of records to show to 10 at a time. As you can see, the results from picture 3 and 4 are just as expected, but in picture 2 (the first of the limited ones) from record 4 on the output is different, leading to the situation that the last record shown here is shown again as the first one of the next partial output and the 10th record on picture 1 (where f_org_lis_id = 1) isn’t shown at all…
I played around a little bit with the number of records to show and the observed behavior gets worse the smaller the number gets.
Is this a known problem (I tried to search for something similar but didn’t found anything) or is there anything wrong with my expectations? Btw., I’m running the actual version (8.00.0047) on Win 8.1 with MySQL 5.6.25, if that matters…
Thanks for any help or hint,
Peter