Hi,
Here the patch
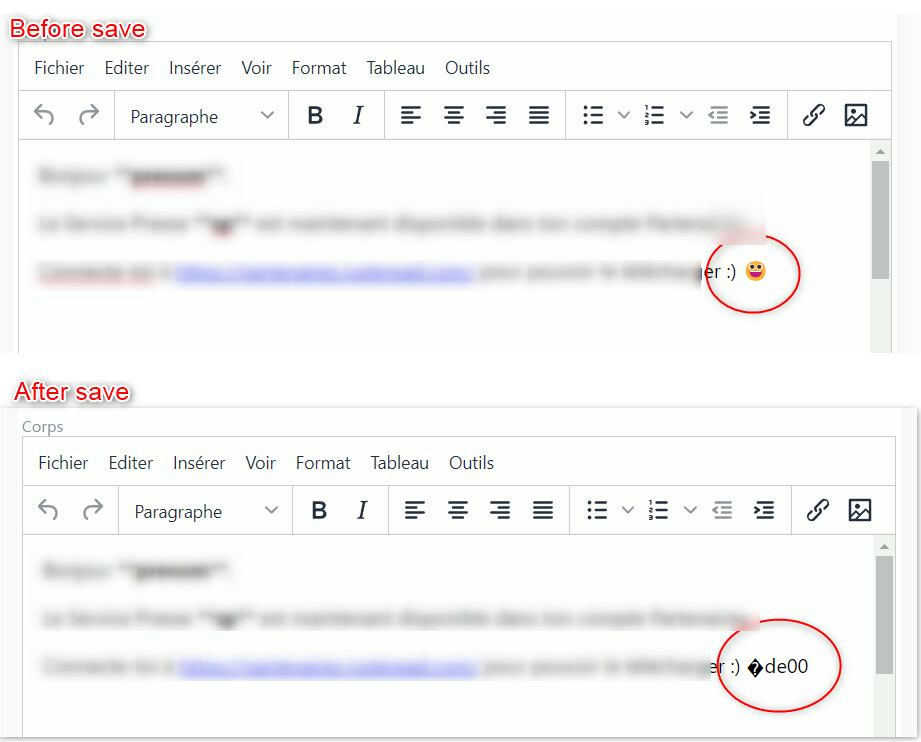
ACTUAL BEHAVIOR
The emoji is replaced with a replacement character followed by the
literal hex string of the low surrogate, e.g.
“Tu continues l’aventure avec nous ! �dd2b”
EXPECTED BEHAVIOR
The emoji should remain intact, as it does on the initial (pre-AJAX)
render and after a full page refresh.
ROOT CAUSE ANALYSIS
File: scriptcase/devel/lib/php/json.php
Class: Services_JSON
Method: encode()
Lines: approximately 326-342 (ScriptCase 9.13)
The buggy code:
case (($ord_var_c & 0xF8) == 0xF0):
// characters U-00010000 - U-001FFFFF, mask 11110XXX
$char = pack(‘C*’, $ord_var_c,
ord($var[$c + 1]),
ord($var[$c + 2]),
ord($var[$c + 3]));
$c += 3;
$utf16 = $this->utf82utf16($char);
$ascii .= sprintf(’\u%04s’, bin2hex($utf16));
break;
The call mb_convert_encoding($utf8, ‘UTF-16’, ‘UTF-8’) on a 4-byte
UTF-8 input returns a 4-byte UTF-16 surrogate pair (for example
D83E DD2B for U+1F92B), not a single UTF-16 code unit.
The expression sprintf(’\u%04s’, bin2hex($utf16)) then emits a
SINGLE \u escape followed by 8 hex digits (e.g. \ud83edd2b), which
is NOT valid JSON. The JSON specification requires surrogate pairs
outside the BMP to be encoded as two separate \uXXXX escapes.
JSON parsers read only the first 4 hex digits of each \u escape, so
\ud83edd2b is parsed as the lone high surrogate U+D83E followed by
the literal text “dd2b”. When rendered to the DOM, the lone surrogate
displays as U+FFFD (replacement character) and “dd2b” remains as
visible text, which matches the observed corruption exactly.
The companion utf82utf16() helper also lacks explicit handling of
the supplementary plane (comment in code: “ignoring UTF-32 for now,
sorry”), indicating this code path was never properly implemented
for characters outside the BMP.
PROPOSED FIX
Replace the 4-byte branch with a correct surrogate pair emission:
case (($ord_var_c & 0xF8) == 0xF0):
// characters U-00010000 - U-001FFFFF, mask 11110XXX
$b1 = $ord_var_c;
$b2 = ord($var[$c + 1]);
$b3 = ord($var[$c + 2]);
$b4 = ord($var[$c + 3]);
$c += 3;
// Decode 4-byte UTF-8 to Unicode code point
$codepoint = (($b1 & 0x07) << 18)
| (($b2 & 0x3F) << 12)
| (($b3 & 0x3F) << 6)
| ($b4 & 0x3F);
// Encode as UTF-16 surrogate pair (two \uXXXX escapes)
$codepoint -= 0x10000;
$high = 0xD800 | (($codepoint >> 10) & 0x3FF);
$low = 0xDC00 | ($codepoint & 0x3FF);
$ascii .= sprintf(’\u%04x\u%04x’, $high, $low);
break;
This patch does not touch the ASCII, 2-byte or 3-byte branches of
the switch, so it is backward-compatible with all existing behavior.
It has been applied in a production ScriptCase 9.13 installation
and fully resolves the issue on Grid pagination.
I sent an email to ScriptCase asking them to create a patch
Guy