
I have a table set to utf8_spanish_ci, with accented characters and Ñ.
But for some time now I have noted that when I do a sc_lookout it retrives the value such as “PE�A P�REZ, RODRIGO” instead of “PEÑA PÉREZ, RODRIGO”, as it is in the table.
I use the retrieved field to load a grid from another table also with utf8_spanish_ci, but then it gives the following error:
An error occurred while accessing the database
Illegal mix of collations (latin1_spanish_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE) for operation '='
select count(*) from item_fabricados where (NombreOperario = “PE�A P�REZ, RODRIGO” and estado <> “C”)
That is new bug SC… Now for each apps you must set collation!!!
Many thanks for your quick answer… but how I can do in the scriptcase apps?
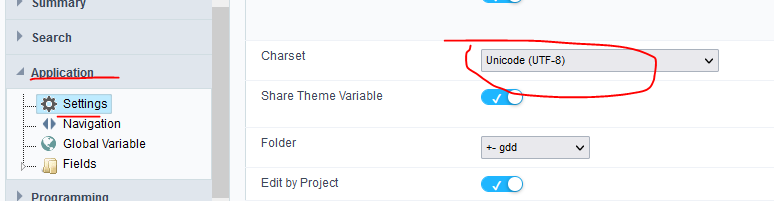
Hi, javi, you must validate the collation for your tables,
If you saved data with the old form create with new SC version, these data already have special characters.
Muchas gracias Alvaro.
Revisé el cotejamiento de base de datos, tabla y campo. Todo está ok.
He creado nuevas aplicaciones de Grid y Formulario enlazados para la misma tabla y ocurre lo siguiente:
Registro nuevo:
El Grid muestra caracteres extraños.
El form muestra Ñ y acentos correctamente.
Registro antiguo:
El Grid muestra caracteres correctamente
El form muestra caracteres extraños.
¿Cómo el el grid y la aplicación muestran caracteres distintos siendo la misma tabla y estando habilitadas en ambas el UTF8?
Por si diera alguna pista, en el ordenador de pruebas con Windows no hay ningún problema, pero sí en el servidor de Linux. ¿Puede faltarme alguna configuración?. Aunque siendo la misma tabla no comprendo porque lo hace bien al app de formulario y no en la del grid.
Estoy muy confuso y algo debo estar haciendo mal. Si se te ocurre alguna idea, será muy bien recibida.
Muchas gracias por tu tiempo y tu ayuda.